Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM

ChatGPT的火爆已经持续了很长一段时间,我们也做了一些研究,试图理解其在投资上的机会,在此分享出来与大家交流。受限于笔者的专业度,难以完全保证内容的准确性,如有错误欢迎指出。本文来自于BEDROCK成员Jimmy,及其和团队讨论记录。
1、大模型进化路径
ChatGPT起源于transform模型,对于模型的细节我们不需要了解太多,更重要的是搞清楚其能力进步的来源和速度。可以说,大模型有两种进步模式:渐进和涌现。
渐进:OpenAI在2020年的一篇论文中指出,在到达极限前,随着模型参数、数据量、以及算力的指数级提高,模型能力虽然也会指数级提高,但是提高的速度很慢,如下图所示:
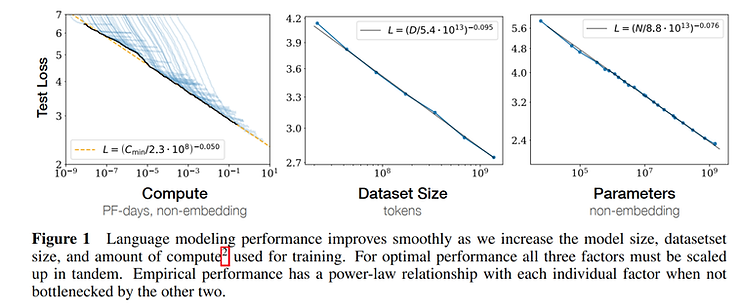
其中横轴是算力、数据量、参数量,纵轴体现了模型的性能(越小越好)。
涌现:2022年,一篇来自谷歌的论文发现,当模型训练的算力量达到一定程度后,对某些任务的处理能力会爆炸性提高,如下图所示:
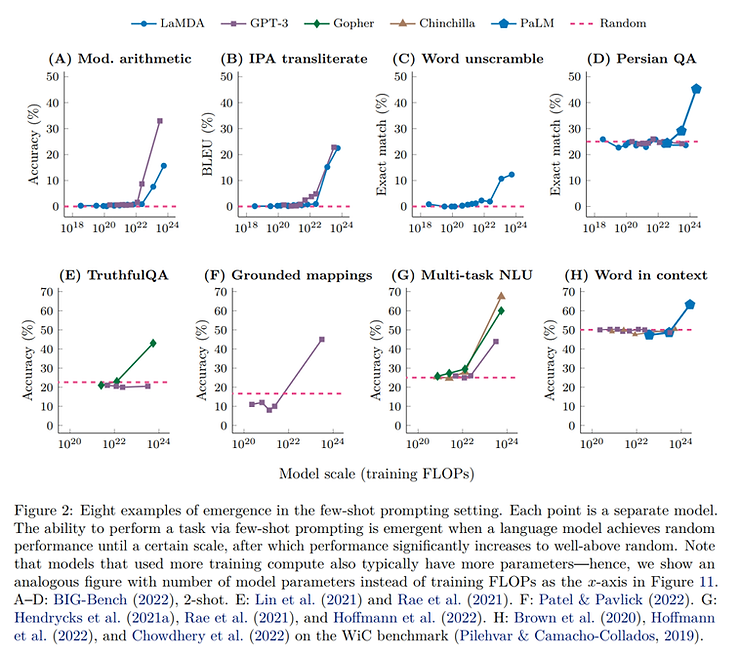
也就是说,算力量达到一定程度后,大模型会突然学会一些能力,这个过程就叫做涌现。研究人员总结了不同大模型涌现出的各种能力,包括加减运算、chain-of-thought等等。可以看出,越是复杂的能力,涌现所需要的算力越多(当然也跟训练的方法有关)。
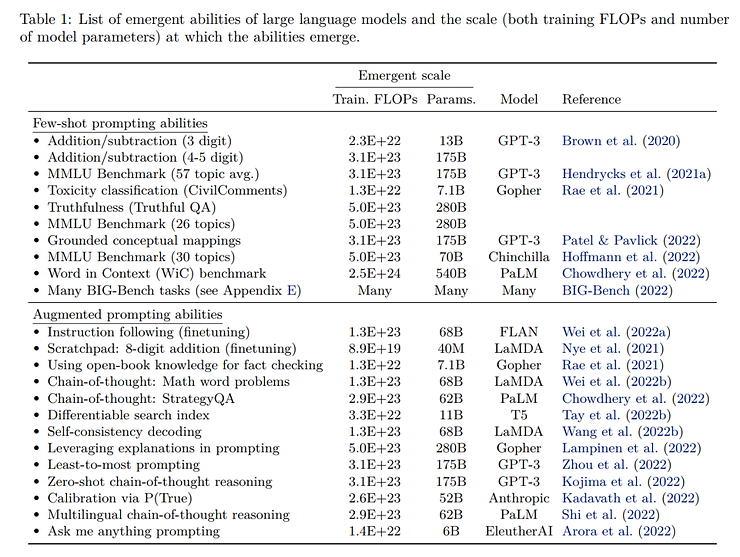
其中,chain-of-thought能力如下图所示:
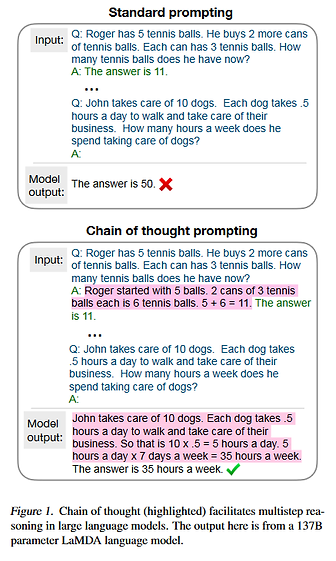
由此,我们可以得出第一个结论:大模型的算力、参数量、数据量还会继续增加,目前还远远没有看到顶点。
2、算力、参数量和数据量的关系
当参数量和数据量增加时,所需求的算力量毫无疑问也在增加。过去,无论是参数量还是算力量都经历了非常快速的指数级提升:
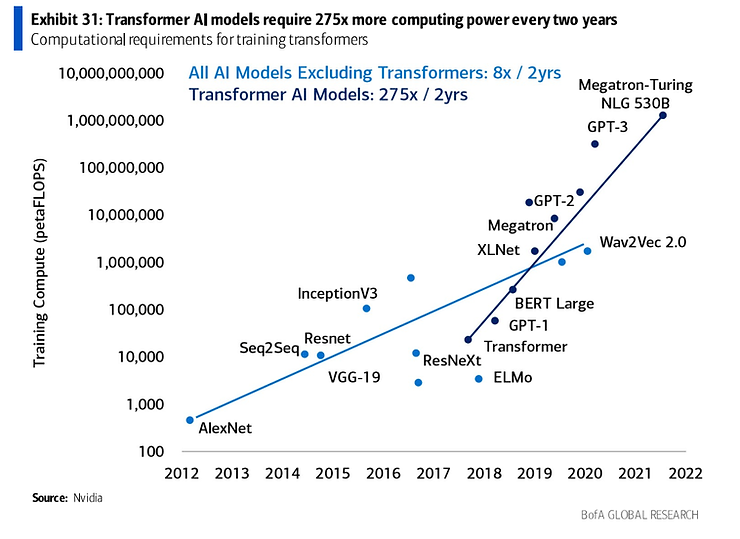
算力的指数级提升
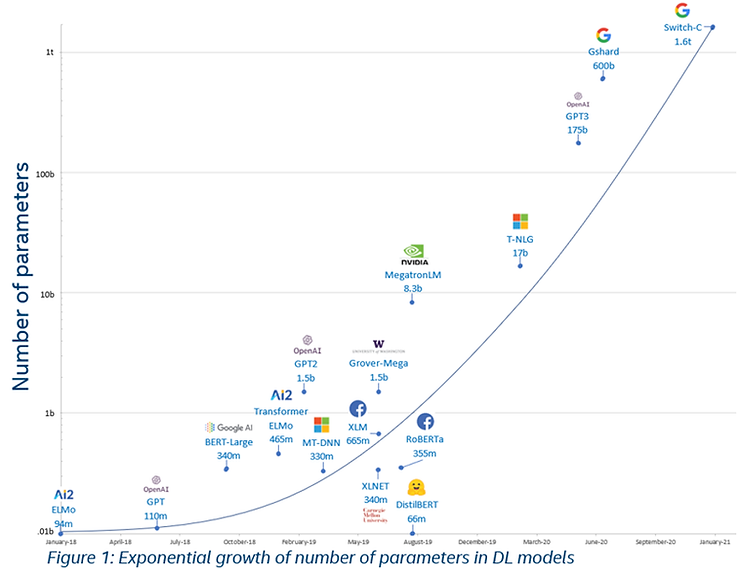
参数量的指数级提升
但是,2022年DeepMind的一篇论文发现,当算力一定时,模型参数量并不是越大越好,而是有一个最优解。图中左一的每一条线上的不同点都代表了同样的算力,可以看出当参数量达到一定数量时,大模型的性能达到最高(图中的最低点)。
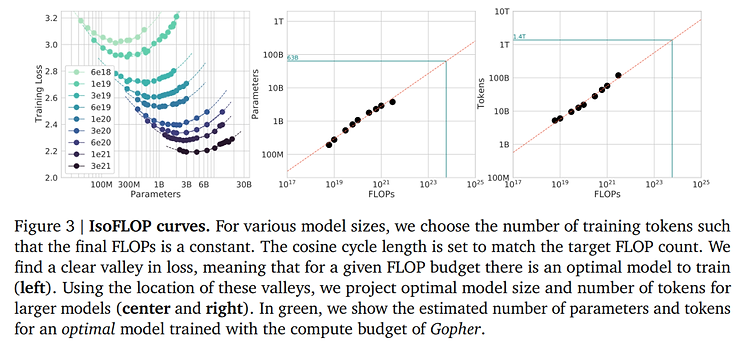
由此,我们可以得到第二个结论:大模型的性能取决于其训练用的算力多少,调整参数量只能挖掘出当前算力水平下的最高潜力。
因此,当评价一个大模型时,算力量而非参数量才是更好的指标。
另外,根据论文中的对比结果可看出,在GPT-3当前的参数量级下,GPT-3并没有达到最优化的性能。因此,我们推测GPT-4 的参数量会比 GPT-3 更大,但不会像GPT-2到GPT-3那样有100倍的提升,而是更多地增加训练用的数据量,从而提高整体的算力用量,达到最优化的状态。

3、投资机会
AI行业的TAM毫无疑问是十分巨大的,但是怎么计算却各有说法。我们按照AI对人类工作效率的提升幅度来粗略计算了一下:
2022年,美国就业人数160m,人均年薪5万美金,假设有30%的人可以借助ChatGPT把效率提高10%(只考虑目前的chaGPT技术),并且这些人的年薪为8万美金,那么提高的价值就有3840亿,即使AI收费只有这些价值的10%,在美国的TAM也有380亿,全世界可能有800亿美元左右。
如果GPT继续进步,在25-30年做到帮60%的人把效率提高30%,平均年薪7万美金,收费保持在10%,那么美国的TAM就有2000亿,全世界就是4000亿。
当然,这仅仅是AI在现有产业中提高效率带来的价值,还有由AI创造的新产业、新功能的价值是无法估量的。
短期:
2021年底office 236m订阅人数(Windows 14亿月活),年费136美元,假设渗透office的50%,将GPT集成到各类办公软件中后,订阅费增加每年100美元(目前charGPT pro是240美元),对应收入12b,相当于22年微软收入(198b)的6%
另外,微软说1%的搜索引擎份额对应2b的广告收入,如果微软能抢到搜索10%的份额(微软目前3%左右),对应20b的增量收入,相当于22年微软收入(198b)的10%
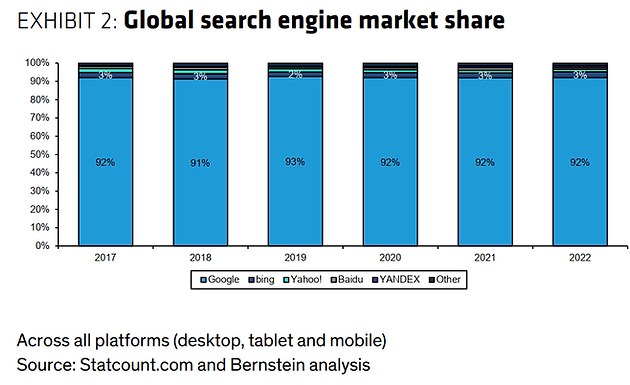
长期:
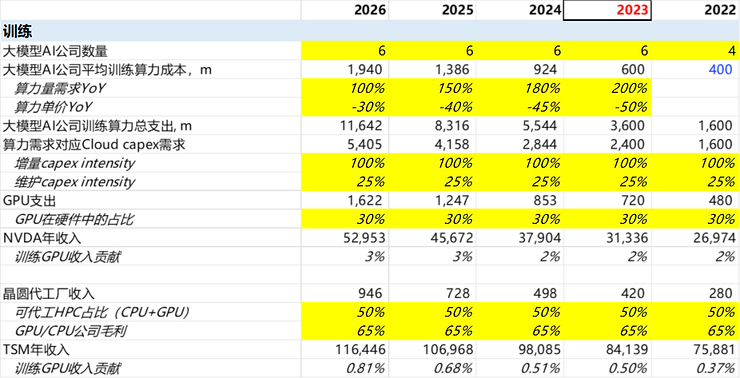
AI大模型对算力的需求主要在两个方面:训练和推理。训练对应的是研发成本,推理对应的是运营成本。
具体来看,DeepMind在19年就亏损了约5亿英镑,OpenAI在22年也亏损了5亿美元。因此每年的算力花费应该就是3-4亿美元的量级。考虑到有能力并且有野心做基础大模型的公司并不多,我们假设22年有4家OpenAI级别的公司,23年及以后有6家。每家算力量的需求以200%的增速增长,而算力的需求则以~40%的速度下降。由此可以算出AI训练所需要的资金成本,然后就可以根据云计算公司的商业模型转换到对硬件的需求,进而算出对NVDA、TSM等公司的影响。
根据计算结果可见,训练给NVDA带来的收入贡献只有2-3%,对TSM的贡献不到1%,可以说并没有决定性的影响。
当AI大模型大规模应用的时候,推理成本就会大幅增加,并且会随着AI推广而快速提高。我们考虑了搜索、聊天、office等AI应用,对推理带来的机会做了粗略的测算。
其中,我们假设微软新必应搜索的渗透率提高到26年的20%,并且AI推理成本在23年快速下降(首次商业化应用,成本的下降空间很大)。尽管OpenAI已经宣布将ChatGPT的定价减小了10倍,我们并不认为这是已经实现的结果,而是快速占领市场的低价策略。
我们预计未来几年AI推理对微软的贡献能达到23%,对NVDA的贡献有7%,而对TSM的贡献只有3%。也就是说,受益于OpenAI最多的是下游应用(微软),其次是GPU等硬件(NVDA),最后才是TSM这种晶圆厂,这也符合半导体行业上游少,下游多的特点。

4、附录 1.NVDA GPU进步速度
H100和A100的性能对比:
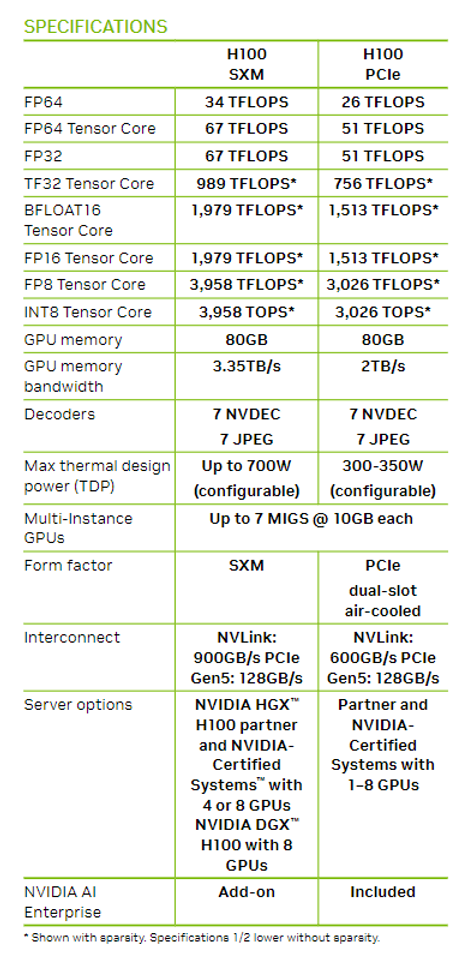
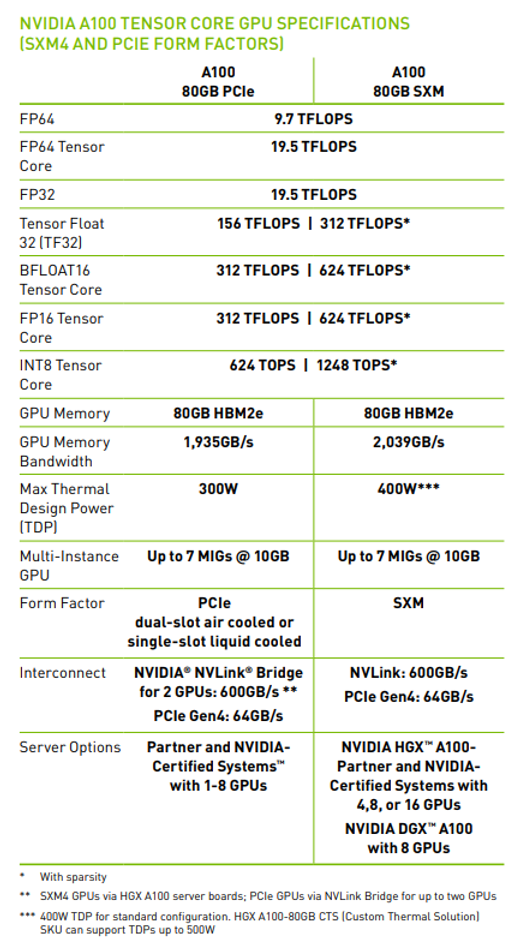
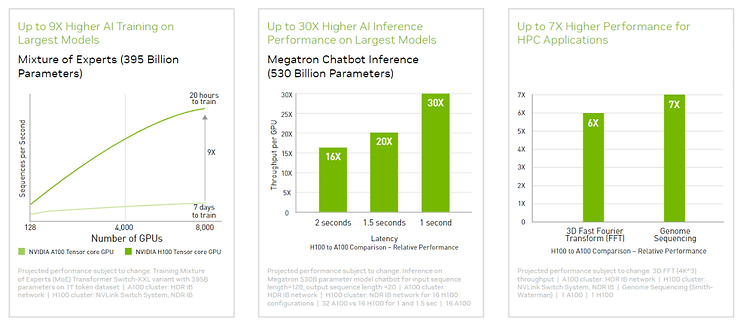
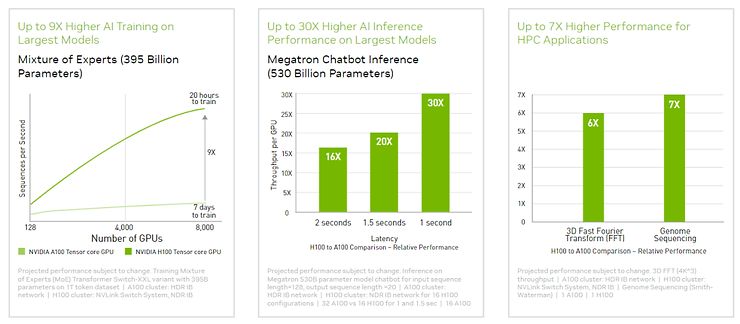

| | H100 80G | A100 80G | A100 40G |
| 发布日期 | 2022 | 2021 | 2020 |
| 发售价格,美元 | 30,865 | 15,000 | 10,000 |
| FP 16,TFLOPS | 1,979 | 624 | 312 |
| TFLOPS每美元 | 0.06 | 0.06 | 0.03 |
| 美元每TFLOPS | 15.60 | 24.04 | 32.05 |
| YoY | -35% | -25% | |
这里是GPU本身性能的进步,考虑到系统级的优化(NVLink、HBM等等),算力单价的下降幅度会更多。
Sam Altman称, 一个全新的摩尔定律可能很快就会出现,即宇宙中的智能数量每18个月翻一番。
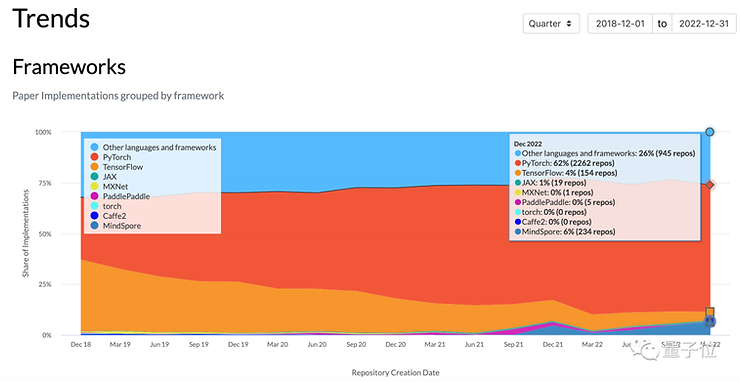
2.技术路线
框架上:GOOG的tensorflow使用率越来越低(4%),目前主流是Pytorch(62%)
5、总结
声明:以上预测部分仅为团队猜想,存在很大的预测偏差的可能性,不作为投资推荐建议


