Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM

智慧也是存储主导的
人和人之间的差距到底来自哪里?我们越来越相信一个判断:真正的差距不在”算力”,而在”存储”。
大脑的处理速度、反应能力,人与人之间差别没那么大。普通人的 IQ 大致在 85–115 这个区间,所谓天才也很少高出两个标准差。而且原始的处理速度过了二十几岁基本就不再提升,甚至开始缓慢下滑。如果智慧只取决于硬件,一个人的能力曲线应该在二十几岁就到顶——但事实显然不是这样,大多数行业里真正的高手都是在四十岁、五十岁才到达自己的巅峰。
差距是从哪里堆起来的?从存储里。从小到大一层层积累的经验、知识、模式——这些才是一个人能力曲线在硬件停止增长之后还能持续上扬几十年的真正原因。说得更直接一点:人和人之间的差距,主要不是硬件差异,而是存储差异。
这个判断对我们而言并不陌生。在另一个层面,AI 系统本身正在经历一次重心迁移——从”计算主导”转向”存储+连接主导”(我们在《AI架构深度研究:存储与连接的时代?》里写过[1])。过去二十年,GPU 算力累积增长约 59,000 倍,但 DRAM 带宽仅增长约 110 倍、互连仅增长约 29 倍——计算端的增速远远甩开了存储和数据搬运。结果是,算力本身依然紧缺,但系统级的瓶颈已经从”算得够不够快”漂向”数据送得够不够及时、存得下多少上下文”。终局看,存储+连接的 capex 占比会反超计算。今天讲的这件事,本质上是同一个 pattern 在另一个维度上的复用——不只是硅基系统的瓶颈在向存储漂移,人的智慧本身也是存储主导的。
标题里的”记忆”,讲的其实就是这件事——人脑里那份被结构化、被反复调用的长期存储。不过这个观察如果只停留在”经验和知识很重要”,还是太弱了——它没有解释为什么有些人看了一辈子的同一个行业,依然只是个平庸的从业者;而另一些人看了同样多的东西,却能看出别人看不到的结构。要回答这个问题,需要把”存储”再精致化一层。关键不在于你存了多少,而在于你存的东西有没有结构。更精确的说法是:
个体的能力 ≈ 编码抽象能力 × 带结构的长期存储
这里的”编码抽象能力”,指的不是先天的脑子快慢,而是把输入转化为可用结构的能力——同一份信息进到脑子里,有人能提炼成三条变量挂进框架,有人只留下一堆碎片,差异就在这里。
为什么必须拆成乘积?因为存储从来不是被动堆出来的。两个人读同一份 10-K,一个人能从里面提炼出三条正交的关键变量,挂进已有框架;另一个人只记住一堆零散的数字。久了以后,前者脑子里是一张结构清晰、节点互相关联的网,后者脑子里是一堆互不相干的碎片。这两个人的”存储量”看起来差不多,但存储的结构质量完全不在一个量级——后者才是真正决定输出的东西。
心理学上的经典实验可以说明这种结构的力量。给国际象棋大师看 5 秒棋局,他们能重建 93% 以上的棋子位置;但如果棋子是随机乱摆、不符合任何真实对局逻辑的,大师的优势就几乎完全消失,接近普通人水平。大师的”超强记忆力”大部分并不是天生的——他们真正拥有的,是一套能把输入快速压缩成结构的能力。当输入符合这个结构,记忆被瞬间调动;当输入不符合,他们就退化成普通人。
所以专家和新手的关键区别,不是硬件层面的”脑子快”,也不是数量层面的”记得多”,而是带着一套更精致的压缩结构去看同一个世界。这套结构的大部分,是慢慢训练出来的。
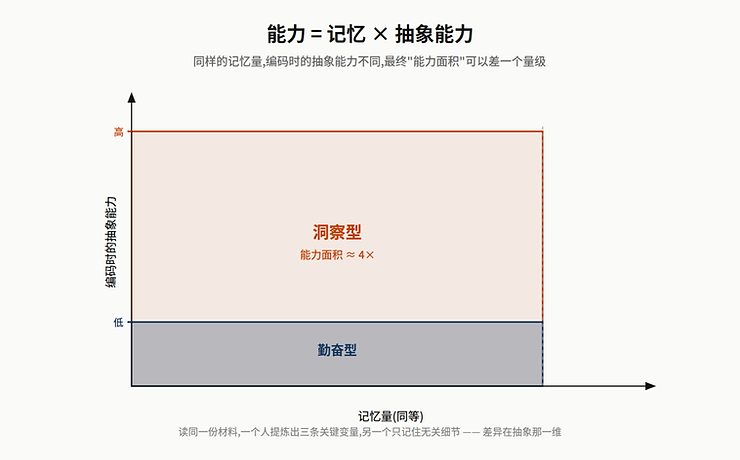
这个框架放到投资这个行当里,解释力特别强。
看过 1000 家公司的人,几乎一定吊打只看过 50 家的聪明人——这是我们这行的常识。但认真追问一下就会发现,这个常识是不完整的。真正的 alpha 不来自”看得多”本身,而来自那些看了同样数量的东西、却能从里面提取出不一样结构的人。
每个做了五年以上投研的人,都遇到过两种同行:一种人把每份纪要都做得工工整整,Excel 拉得密密麻麻,但你问他这个行业的核心变量是什么,他会给你一个教科书式的答案;另一种人看起来工作量没那么大,但他跟你聊一家公司的时候,能一针见血地指出真正的 bottleneck 在哪里、管理层的激励结构和股价表现之间有什么隐秘错位、这个行业过去十年的周期为什么这次可能不一样。两个人读同一份材料、参加同一场电话会,但他们脑子里最后沉淀下来的东西,完全不在一个 tier。
投资圈常用”思维模型“这个词来描述这种差异:脑子里用来组织信息的那套结构不一样,同样的输入就会输出完全不同的可交易命题。好的思维模型不只是记住事实,而是决定了你如何把事实之间的关系编码下来——哪些是主变量,哪些是噪音,哪些信号之间有隐秘的因果链。这套思维模型的好坏,才是乘积公式里真正起作用的那一项。
投研这个行当里真正稀缺的从来不是勤奋,也不是聪明,而是能把一堆看似无关的信号压缩成一条可交易命题的能力。
这里要说一件反直觉的事:任何一家公司的研究 nuance,都是无穷无尽的。你可以读一辈子它的年报、可以和 CEO 每周见面、可以拿到所有的运营数据——你依然研究不完。更麻烦的是,“穷尽式研究”本身就是一个错觉——事实反复证明,连公司内部人员、甚至管理层本人,对自家公司未来的判断都经常出错。如果你相信”只要看得够多、问得够细,就能得到正确答案”,你大概率会在无限的细节里溺水,最后带着一种虚假的 conviction 做决策。
真正的解法是反过来的:不追求穷尽,而是把复杂问题结构化成几个固定的压缩维度。BEDROCK 内部把任何一家公司的研究压缩成三个互相咬合的框架——
这三个框架的意义不是”比别人想得更全”,而是强制你在无限的细节里只保留那些真正会影响最终交易决策的变量。研究这件事,从”尽可能多地搜集信息”,变成“在一组有限变量上的持续校准”——我们不再需要”知道这家公司的一切”才能做出有 conviction 的判断,只需要知道那些会移动这三个框架中任何一个变量的信息。剩下的所有 nuance,哪怕再有趣,都可以暂时搁置。这才是思维模型真正在 P&L 层面起作用的地方。
而这套框架本身,不是从任何一本投资书里抄来的。它是一次次踩坑、一次次被市场教育、一次次在 drawdown 里保留下来的认知修正一层层叠出来的结果。换句话说,框架本身就是个性化思维模型最典型的形态——它是通用投资方法论(DCF、五力、护城河)和我们自己判断(踩过哪些坑、相信哪些变量更重要)的交点。
这个框架最近让我们重新想的一件事,是 LLM 到底在哪个层面上改变了人的能力结构。
一个很容易产生的错觉是:大模型越来越强,人的能力正在被整体拉高。但用上面这个乘积公式去看,事情要微妙得多。
大模型的进步,是在不断抬高一个标准化的”智力基础”——所有拿到它的人,起点的算力都是一样的。这件事对能力结构的影响是两面的:它确实让每个人的下限抬高了,但也让“下限”本身变得廉价。当所有人都能让模型帮自己写一份像模像样的行业分析、拉一张干净的财务模型、翻译一份外文年报的时候,这些工作的边际价值就被压到了接近零。这和二十年前 Excel 和 Bloomberg 的普及对这个行当的改造是同一个道理——工具越标准化,依赖工具本身的那部分能力就越不值钱。
但真正关键的问题不在这里。关键在于:模型自己也在学越来越强的压缩能力。
过去两年,前沿模型的 reasoning 能力、上下文长度、结构识别能力都在显著提升。很多原本属于特定行业”独门框架”的东西——医疗诊断的决策树、法律文书的结构、代码 review 的模式——正在被训练进垂直模型或者专门的 agent 产品里。金融投研方向也一定会走到这一步,只是时间问题。
这里需要承认一个对立的乐观叙事:有人会说,模型吸收标准化工作之后,人的注意力反而被释放出来,可以投入到更高阶的判断上——这不是零和竞赛,而是分工重组。这个说法并非没道理。但回看过去每一次工具革命——从 Excel 到 Bloomberg 到量化——现实更接近”军备竞赛”而不是”分工重组”:每次工具进步都会把原本赚钱的能力变成入场券,能力要求整体上移,真正赚到超额收益的人数反而减少。没有理由相信这次会不一样。
所以结论很清楚:alpha 的定价会持续向上漂移。十年前靠”会用彭博、会建 DCF、会读英文年报”赚钱的人,今天已经赚不到这个钱了——这些能力被工具完全吸收,变成了入场券。未来十年,”会结构化地阅读公司、会快速提炼行业核心矛盾、会用标准框架做比较分析”这些能力,大概率也会被 agent 逐步吸收,变成新的入场券。
回到开篇那个同构:这是同一个漂移规律的两个版本——在 AI 架构里,capex 从 GPU 漂向 HBM 和高速互连;在投研行当里,价值从”会用工具”漂向”有自己的思维模型”。当某一层能力被标准化,价值必然往它之上的层级转移——这条规律比任何具体的技术周期都更长寿。
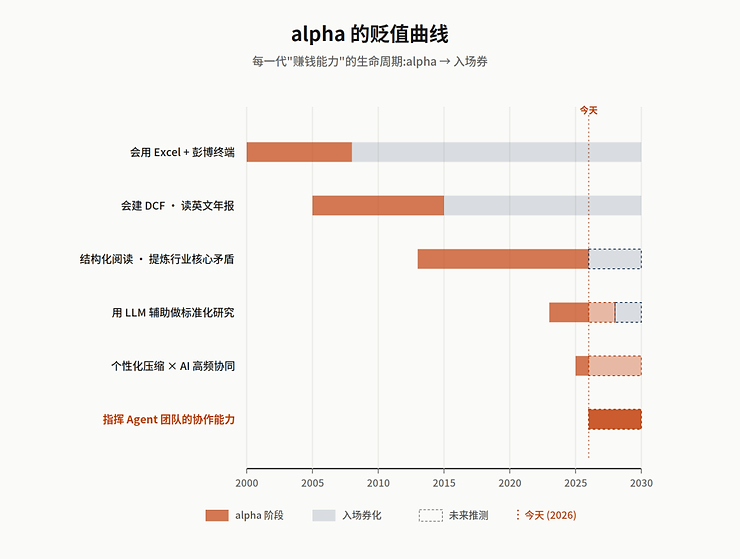
如果价值必然向上漂移,那么真正可持续的 alpha 就变成了一个具体问题:它会停在哪一层?前面讲的”个性化思维模型是最典型的压缩结构”——这句话到底凭什么能成立?它为什么比通用模型贬值得慢?
我们的答案是:来自那些贬值速度最慢的思维模型。这里有意避开了”护城河”这个词——不存在永久的护城河,只有贬值速度的差异。
这里需要区分两种思维模型。一种是通用模型——把一个行业的基本逻辑抽象成可复用的框架,比如 Porter 五力、DCF、价值链分析。这类模型的公共性越强,越容易被 LLM 吸收,因为它们本身就是公开语料,贬值速度最快。另一种是个性化模型——带着你自己独特经验、偏好、判断、失败教训一层层叠出来的结构。BEDROCK 的 CA × Runway × 定价三框架就是这种个性化模型的一个具体形态:它用的是公开的投资方法论(护城河、增长、估值)作为骨架,但每一个维度的打分权重、每一次校准的阈值、每一次”为什么这次不一样”的判断,都是我们自己踩坑后沉淀下来的。
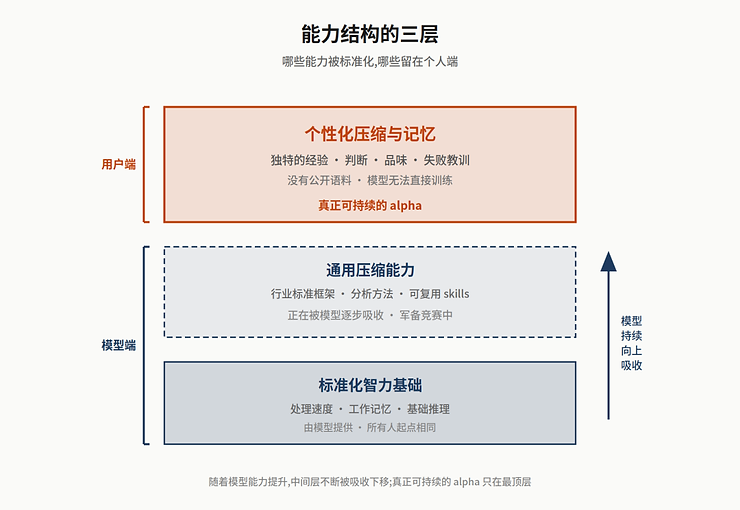
这类个性化模型贬值更慢的原因,不是”它没有公开语料所以模型学不到”——随着 personal memory、RAG、垂直 agent 这些技术路径的推进,个人经验被逐步数字化、被模型调用,只是时间问题。真正的原因是:它根植于你自己的犯错史。每一次踩过的坑、每一次被市场教育的痛感、每一次在 drawdown 里保留下来的认知修正,是一种必须经由时间和代价才能积累的结构。模型可以学你的 output,但很难复制你产生这些 output 的那个过程——这个 gap 在可预见的未来里是真实存在的。
更重要的是,这类个性化模型决定了你会问什么问题。同样一个大模型,一个资深投资人能把它调教出完全不一样的深度,根本原因不是他”prompt 写得好”,而是他知道什么问题值得问、知道答案的哪一部分值得追问下去、知道模型的哪一类输出可以信、哪一类必须自己再验证一遍。这套”问问题的能力”本身就是个性化思维模型的外显。
LLM 时代真正的分化不是”会用 AI 的人和不会用的人”,而是带着丰富个性化思维模型去使用 AI 的人和把 AI 当通用搜索引擎使用的人。前者相当于把自己多年积累的结构,和一个具有标准化高智力的新同事嫁接在一起,能力上限被显著抬高;后者只是在消费模型的标准化输出,能力上限就被模型的平均水平封死了。
未来的 alpha,会越来越集中在那些既有深度个性化经验、又愿意用 AI 高频 offload 标准化工作的人身上。
到这里还漏了一层——而这一层的含义可能比前面讨论的都更深。
前面讲的”个性化思维模型 × AI 协同”,场景默认还是”一个人 + 一个大模型”,本质上还是个人能力的延伸。但这只是过渡形态。真正的下一代工作方式不是这样——它是一个人指挥一支由几十个 agent 组成的团队同时并行工作。这件事看似只是”用更多 AI”,其实对个人能力的要求是一次根本性的转变。
转变在哪里?在过去,一个分析师的产出受限于他自己的脑子带宽——他能在一天里读多少份文件、跑多少模型、想清楚多少问题。AI 出现之后,这个瓶颈被部分打开,但只是部分,因为他还是一个人在和一个工具打交道。而当 agent 真正成熟之后,瓶颈会从”个人算力”彻底转移到一个完全不同的地方——你能不能把一个复杂任务清晰地拆解成 20 个并行的子任务,把每个子任务交付给合适的 agent,然后准确地验证它们的输出,再把结果整合成一个有机的整体。
这是一种非常不同的能力。它对个人原始算力的要求反而降低了——你不再需要亲自做每一件事;但它对框架清晰度和抽象能力的要求,反而显著提高了。原因很简单:一个混乱的脑子带不动 10 个 agent。如果你自己都说不清楚一项研究应该被拆成哪几个步骤、每一步的输入输出是什么、什么算”做对了”——那你就根本没法把任务交付出去。你只能继续亲力亲为,继续被自己的算力上限封死。
换句话说,框架的清晰度直接决定了你的指挥半径。一个有清晰 CA × Runway × 定价框架的投资人,可以让 5 个 agent 同时处理 5 家公司的初步分析,因为他知道每个 agent 应该输出什么、哪些维度的输出可以信、哪些必须自己再校准。一个没有框架的投资人,即使把同样的 5 个 agent 给他,也只能让它们做一些零散的查资料、写摘要的工作——因为他没法把”研究一家公司”这件事拆解成可交付的子任务。
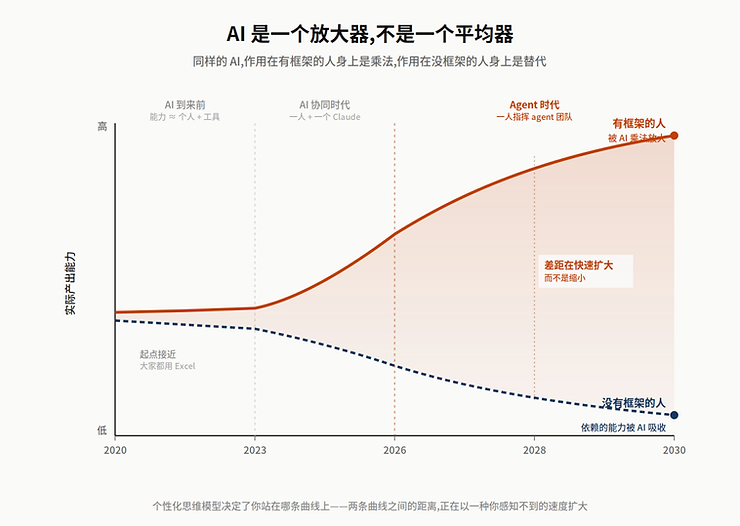
所以前面讲”个性化思维模型贬值最慢”,只说对了一半。更完整的说法是:个性化思维模型不仅贬值最慢,它还是你未来能否带得动 agent 团队的前提条件——框架同时也是你指挥 agent 的语言,越清晰、越精确,你的协作半径就越大。未来真正稀缺的人不是”懂得最多”的人,也不是”最会用 AI”的人,而是那些能把自己的研究方法论清晰到可以交付给一支 agent 团队的人。
这件事不只在投研里成立。软件工程领域已经在更早地经历同样的转变——PingCAP 的 CTO 黄东旭在一次访谈里提到,他主导的一条产品线只有一两个开发者,过去三个月干了传统软件公司 100 个人一年的事,公司内部 90% 的代码由 AI 自动生成,人类工程师不再阅读代码细节,只专注于工程架构这些更上层的事情。”传统的软件工程已经终结了”,他说。这背后的能力被他命名为 “Harness Engineering“——管理一支由不同角色组成的数字化团队的能力,这和投研里”用一套清晰框架去指挥 agent”讲的是同一件事。
当执行的边际成本趋近于零之后,稀缺的就不再是你的执行力,而是你的”想做什么”。瓶颈会迅速漂移到上游——漂向那个能源源不断提出新问题、新角度、新假设的人。提需求本身,变成了新的核心能力。
这里有一个容易被忽略的推论:这个转变对一类人特别不友好——那些方法论高度依赖”隐性经验”和”我看一眼就知道”的直觉型从业者。这类方法论在过去是 alpha 的重要来源,但在 agent 时代会变成 bottleneck——因为隐性的东西没法被指挥、没法被并行、没法被 scale。反过来,那些愿意花时间把自己的隐性经验显性化、结构化、变成可以交付给 agent 的框架的人,会被这个时代显著放大。这件事和”勤奋或不勤奋”、”经验深或浅”关系不大,真正决定命运的是你是否愿意把自己的直觉语言化。
但”指挥半径”还不是 AI 时代能力放大的全部。除了”同时能做更多事”,还有一件事在悄悄发生——你能尝试的想法、能试错的次数,也在被极大地放大。这一点我最近有非常强烈的体感。AI 时代的反馈链路被压缩到了一个前所未有的程度——你提一个想法,几分钟之内就能看到结果;一个错误的假设,几小时之内就能被证伪;一个原本需要几周才能验证的研究角度,现在一个下午就能跑完。这种短反馈循环本身就是一个独立的放大器:它让那些本来就有源源不断 idea、敢于试错、愿意快速 iterate 的人,创造力被极大地放大。我必须承认,这种工作方式有一种接近上瘾的感觉——每一个新想法都可以在一杯咖啡的时间里看到回报,每一次失败都来得太快而无所谓痛感,你会停不下来地想”那再试试这个角度?”。一天结束的时候,你会发现自己走过了一条比过去整整一周更长的认知路径。
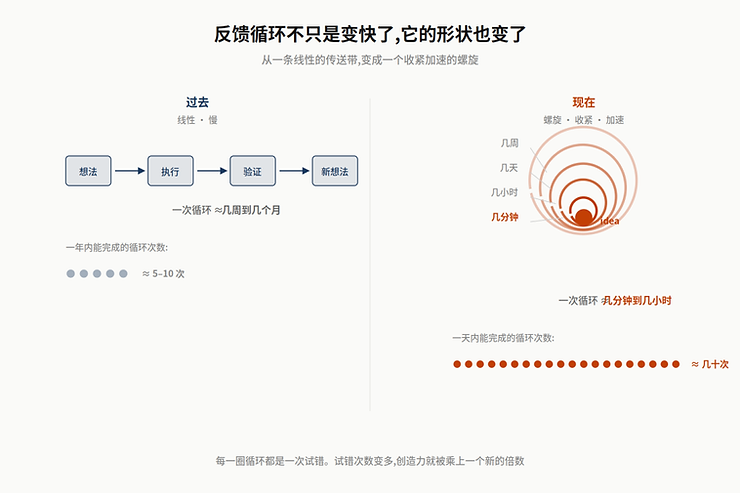
所以更完整的图景是这样的:Harness Engineering 让你在同一时刻能指挥更多 agent 并行工作(执行半径的扩张),短反馈循环让你在同一时间内能试更多想法(探索半径的扩张)。这两种扩张不是替代关系,是乘积关系——最强的人,既有清晰到可以指挥 agent 团队的框架,也有源源不断的、敢于在反馈循环里被立刻证伪的想法。回到开篇那个公式,AI 时代的个体产出其实可以再拆一层:执行半径 × 探索半径——前者靠框架的清晰度,后者靠反馈循环的短和你愿意往里面塞多少想法。
上面讲的都是”人”这一侧——思维模型是如何被结构化、指挥、放大的。但值得单独拎出来的一件事是:“带结构的个性化存储”在硅基世界也正在发生,而且正在重新定义什么才是真正的存储需求。
今天的存储需求,大部分是 write-once-read-rarely——文件、日志、网页快照存进去,99% 的数据被访问 0 次,所以”永远不删数据”的哲学能成立。但 agent 时代的”个性化记忆”完全不同:它是 write-once-read-many-times,每一条原始信息都会被处理成多种 representation——向量(embedding,把每段文字翻译成一串能按”意思”检索的数字坐标)、知识图谱节点、时间戳元数据、语义聚类、用户画像 fingerprint——然后被 agent 在每次交互中反复 query、反复重组。
这带来的最大误解,是以为”存储需求”会像过去一样主要是容量层面的增长。事实上更关键的是一次访问模式的根本改变:同一份数据被放大成多种结构化表示、被反复读取、被交叉引用——容量只是温和增长,但带宽和 IO 强度会经历一次更陡的扩张。容量是线性的,IO 是更陡的曲线,这两者的剪刀差才是真正定义下一代存储瓶颈的地方。
而且这里有两个容易被忽略的二阶判断。
第一,技术进步不会减少这个需求,只会增加。一个常见的直觉是”未来 embedding 技术会更高效,所以存储需求会下降”。事实相反——embedding 技术越强,每条原始数据被翻译成的反应框架就越丰富、维度越多、关联图谱越密。一个 768 维的 embedding 可以表达几百种反应方式;一个 8192 维的 embedding 可以表达几千种。每一次”理解能力”的升级,都会让同一份原始数据产生更多、更复杂的 derived representation。存储需求不会随着技术进步而下降,它只会随着”每份数据被理解得多深”而持续上升。
第二,不同 agent 的核心差异,会越来越集中在 agent memory 层。两个 agent,即使背后跑的是同一个大模型、拥有相同的原始对话历史,一个用的是简陋的 embedding + 稀疏的 graph,另一个用的是精细的 embedding + 密集的 graph——后者能”想到”的关联和前者不在一个量级。agent 的能力差异,会从”谁的底层模型更强”逐步漂向”谁的记忆架构更精致”。而记忆架构的精致程度,几乎完全取决于它背后的存储系统能承载多高的 representation 密度和多快的访问频率——这是另一条把价值从”算力”推向”结构化存储”的力量,而且它作用在离用户最近的那一层。
所以对你个人而言,这件事的具体含义是什么?
你真正的护城河不在你脑子转得多快,而在你沉淀了什么样的思维模型、以及这些模型清晰到什么程度可以被你自己之外的”算力”调用。
这件事对投研有一个具体、也更硬的推论——
不要把自己的判断外包给模型。这不是”你会变成更平庸的版本”那种软性理由,而是一个关于资产折旧的现实:你的个性化思维模型是一个需要持续再投资的现金流资产。每一次你遇到一个判断问题,认真思考然后犯错或做对,都是对这层结构的一次更新;每一次你把问题直接丢给模型、接受它的答案,都是跳过了一次再投资。短期看你效率更高,长期看你的 differentiation 在以一个你自己感知不到的速度折旧。一年之后,你和”只会用 AI 的新人”之间的距离会被拉近,而不是拉远。
正确的姿势是反过来的:让模型帮你 offload 标准化工作,把节省出来的时间全部投入到那些只有你自己才能沉淀的东西上——看更多的公司、和更多的管理层聊、经历更多的周期、犯更多你自己的错误、做更多你自己的修正。然后,把这些沉淀下来的东西写下来、结构化、变成可以教给 agent 的框架。
在一个算力越来越便宜、通用思维模型越来越标准化的时代,只有那些长在你自己身上的、带着你独特印记的结构,才是真正能穿越周期的 alpha。
也才是真正意义上的,你自己。




