Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM

在GTC上,黄教主放了两张非常有意思的图:
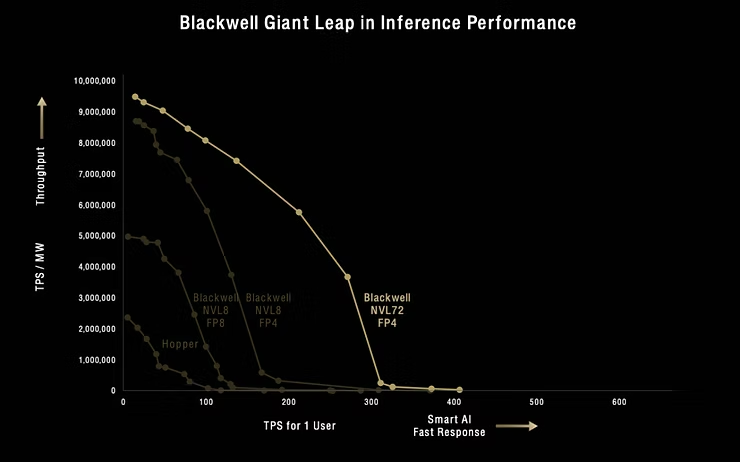
上面两张图:
GPU越先进(B200相对H100更先进),精度越低(FP4相比FP8精度更低),所需要的TPSfor 1 user 越低,1MW服务器每秒能输出的tokens越多。
此外,连接方式对throughput也有很大影响,值得深入讨论一下:
在同样是Blackwell、FP4的条件下, NVL72和NVL8在需要的Tokens per second(TPS)per user高于100时,会产生显著差异:
小结一下,当TPSfor 1 user需求超过100时,Blackwell NVL72相比NVL8就能发挥显著优势,相比Hopper等更是优势碾压。
具体来说,1MW的NVL8 Blackwell数据中心:
如果用户的任务比较简单,比如只是提问和回答问题,一次提问要消耗90个token,每秒并发需求是10万用户(峰值用户10万大概对应1000万日活用户),如果只要求TPS for 1 user达到10,即等待9秒回答这个提问,那么1个1MW NVL8 Blackwell数据中心,对应吞吐能力在900万Tokens/s可以满足要求。
如果要改善用户体验,比如让用户等待时间缩减为0.9秒,即需要TPS for 1 user达到100,这个时候同样的1MW数据中心只能提供每秒600万Tokens(而不是此前900万),会导致可以服务的并发需求缩减为6-7万人,意味着只能服务600-700万日活用户,相对之前的服务能力打7折。
小结一下,降低用户体验(降低TPSfor 1 user),可以提高数据中心服务能力(即提高每秒Tokens吞吐能力)。两者有此消彼长的关系。
目前的数据中心普遍的要求是20 TPS for 1 user(对应每秒30-40个汉字,26个单词),从这个角度看目前多卡互联对推理的意义就很小。
另一个角度来看,人类的阅读速度只有每秒~5个汉字或单词,如果AI的应用是通过chatbot的交互形式,也不需要太高的TPS。
但是,如果对AI的应用变成以Manus、DeepResearch为代表的Agent,就会需要超高的TPS,届时对TPS的需求很容易超过100,甚至高很多。
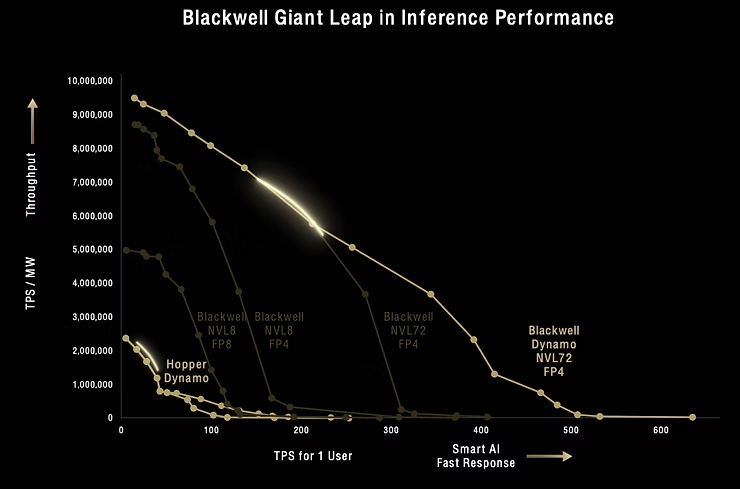
新发布的Dynamo推理框架也是一样的逻辑,对TPS for 1 user大于250时很有用,但是低于250时就是大材小用没有必要。
在Chat应用中:
服务峰值1万用户(对应服务日活用户100万),每个任务需要900 tokens,那么每秒throughput 需求就是900w tokens。如果使用Blackwell NVL72的数据中心:
目前以简单任务为主的应用中,提供情形1的体验就足够了。
而在Agent应用(如Manus、Deepresearch)中:
服务峰值1万用户(对应服务日活用户100万),任务复杂了,完成一个任务需要90万tokens(是之前的1000倍),每秒throughput 需求变成90亿 tokens。如果使用Blackwell NVL72的数据中心:
在同样用户体验下,要服务100万日活用户,150万张NVL72卡能做的事情,NVL8来做需要6x的卡。
如果从简单问答的AI需求变成复杂任务需求,在可接受体验下(复杂任务相比简单任务需要等更长时间),服务同样规模的用户,即使在卡从NVL8升级到NVL72卡后,卡的需求量会提高1500x。
总的来说,长推理复杂任务会加强NVDA的优势,因为一个回答的tokens越多,越需要高TPSfor 1 user,这样才能把回答时间控制在一定范围内。
如果按照上文假设的服务100万日活用户的Agent需求,以使用NVL72为例(即Agent测算的情形2),需要150万张B卡。如果每张卡3.5万美元,假设折旧5年,每个用户每年的卡成本就有1万美元,加上其他服务器成本、运维成本,Agent服务提供方如果要不亏钱,从每个用户身上至少要收到2万美元,而如果想获得合理回报,至少收到5万美元。
美国人均可支配收入在6万美元,即使Agent可以达到替代1个人的能力,2-5万的收费也太高了。况且Agent要进步到完全替代1个人还需要时间。
但是,如果能通过软件优化或者硬件进步将推理成本继续降低10倍,并且Agent进步到能够完全替代1个人,那么每年每个用户只需要花费5000美元,这个收费水平就很有吸引力了,而且Agent公司有可观回报。目前看硬件优化对推理成本的降低,2年~30x,如果这个速度可以延续,再加上软件优化,Agent走通还是很值得期待。
最后,以上的结论都是根据NVDA现在公布的服务器推理性能曲线图计算出来的,如果软件进步或者硬件进步导致这个曲线发生变化,对应结论也要重新计算。比如NVDA今年下半年推出的Blackwell Ultra、明年推出的Rubin,以及Deepseek可能会发布新的模型、新的推理优化方法,都会导致上面的结论发生变化。



